
 Demand Modeling Explained - Part 2: Why Demand Modeling
Demand Modeling Explained - Part 2: Why Demand Modeling
Part 2 - read the first here
This part highlights the largest differences in approach between traditional statistical forecasting and demand modeling. These differences together are the key enablers that allow breaking through the glass ceiling of achievable forecast accuracy self-imposed by the traditional methods.
This part may get a bit technical in places. Hence the "technical" tag, which I will start adding to any future posts as well when these are more technical than usual. I will also retro-actively apply these to some past posts, since there are a few that are certainly that. Even so, I believe that one may read over the technical terms without loss to the overall message.
Also note that for now, in this part, we will ignore causal effects, outliers, and even trends and seasonality. These will be covered in depth in later parts. For simplicity of explanation we will assume that the demand history for both types of approaches is free of such influences.
The essential differences between traditional approaches and demand modeling can be classified in three distinct categories:
- Input - they take different input, or the same type of input in different granularity
- Process - the calculations performed on the inputs are different or performed in different sequence.
- Output - the outputs are different too, different forms and different granularity.
Each of these is described below. Let's start with the process.
The process
The difference in calculation process between the two approaches starts with a difference in the order in which steps are taken. Traditional forecasting starts with a given algorithm and goes through the following steps for it:
assuming a probability distribution of the errors determine parameters of the algorithm to fit the known historic data points as closely as possible
determine the error and a measure of overfit
pick the next algorithm and repeat
after all algorithms are done compare error and measure of overfit of each, and pick the one with the best trade-off.

Demand modeling on the other hand reverses the determination of distribution and error:
- Determine the probability distribution of the actual demand that minimizes the error
- Determine future demand quantities based on this probability distribution
Done.
Other than a reversal of the key parts of the process there are a few other note-worthy points to extract and extrapolate from the above:
- Traditional forecasting does NOT determine variability of the actual demand, but rather of the errors relative to the chosen forecasting algorithm, and will have different values depending on the chosen algorithm. Demand modeling on the other hand is capable of forecasting the true demand with all its inherent variability, with no artificial additives.
- Traditional forecasting needs to make a trade-off between minimizing the forecast error and avoiding the dreaded overfitting. Demand modeling is not so encumbered. It can find the probability distribution that minimizes the error in absolute terms without having to water it down in fear of overfit.
- The probability distribution of the errors in the traditional approach needs to be determine beforehand, before application to any given series of data. In almost all cases this distribution is assumed to be Gaussian (also known as a normal distribution), since it is so easy to work with. This is one of many reasons why these approaches perform so badly for all but the fastest moving items, since those are the only ones where the Gaussian assumption is valid.
- Similarly, many metrics - such as least squares - used to determine the error favor symmetry (such as exhibited by the normal distribution). In cases where a symmetric distribution is inadequate (typically more than 90% of all demand patterns in a given supply chain) these metrics will actually penalize asymmetric results even though they are in most cases more accurate than symmetric ones.
For demand modeling the primary exercise is to determine the probability distribution that minimizes the error. Rather than try to iterate through a number of known distributions and pick one based on certain criteria, a single overall distribution is created and its parameters determined. The question I get asked frequently is "which distribution is this single distribution?". The person asking is usually statistically savvy with deep knowledge of all the commonly used distributions, and expecting the answer to be one of those. It is not.
The probability distribution used by demand modeling is a so-called compound distribution.
This is a distribution determined by combining multiple other distributions. Each demand modeling system may do this differently, and each implementation of a single system may be based on a different collection of distributions that get compounded. Two important distributions to include that drastically improve accuracy for a baseline forecast are one for quantity per order line, and one for order line frequency. The future part in this series that covers order lines will explain some of the reasons why in greater detail. One could consider including distributions for various types of uplifts as well, such as for promotions, which explains how the collection of distributions to include may differ: if there is no significant promotional activity one can simply omit that aspect. Similar considerations can be used to determine inclusion of exclusion of distribution of a number of different aspects that contribute to the demand pattern. Usually the two main criteria are: 1) is an aspect significant, and 2) do we have historic data for it.
What has been established over the decades is that the various distributions that contribute to the total compound can be very accurately and generically represented by simple 1-, 2- or 3-parameter distributions; a different one for each type of contributing factor.
The inputs
In order to maximize accuracy, a number of the contributing factors for a demand model require different types of source data or more granular data than the traditional approaches can accept. For example, to determine the distributions of the above-mentioned order line quantity and order line frequency one obviously needs order line data. Thankfully, this information is usually readily available in either sales order or shipment order data in any given ERP system. Due to the selective nature of contributing factors to include, demand modeling gracefully accepts less granular data to the point where it may even deteriorate to a level of quality of forecast that is on par with traditional approaches when no data other than periodic demand data is available. The great thing is that this can be by individual item-location, allowing highly heterogeneous data to be provided: where granular data is available accuracy can be improved, where it is not available it stays at similar levels as traditional forecasting.
One thing many academics will state is that there is a theoretical limit to the accuracy one can achieve when forecasting demand. They are correct.
However, where that theoretical limit is located, is very much dependent on the data the forecast is based on. When the forecast is based on aggregate data, such as weekly or monthly historic demand quantities that theoretical limit is a lot lower than when it is based on daily data or better still individual order lines. The reason traditional forecasting approaches use weekly or monthly data is not because of accuracy, but because it is just plain easier to do so. The logic is as follows:
when you aggregate you lose noise, the data gets smoother, and forecasting is easier to do.
What most people do not realize is that:
when you aggregate you also lose signal, and forecasting becomes less accurate, lowering the maximum achievable accuracy.
If you had not realized this before, please let it sink in before reading on. This is an important point. When you aggregate you lose nearly as much signal as you lose noise. Signal that can never be retrieved again at the aggregate level. We gain ease at the expense of accuracy when we aggregate.
More advanced forms of demand modeling extend this same concept in any imaginable way possible. For example, in recent years much headway has been made in improving forecast accuracy based on big data, gleaned from websites, social media, and so forth. Naturally the burden of collecting, organizing and cleansing source data increases many times over, which does not make it an appropriate proposition for many scenarios. However in the areas of trade promotion planning and new product introductions the witnessed benefits are so great that it easily justifies the additional effort.
The output
In the preceding sections I have described how the process of demand modeling is different from traditional forecasting and what that means in terms of the input it can accept. That same process brings another great benefit, which is the form in which it can output its results.
Statistical forecasting strictly speaking is a misnomer, since it does not even output a forecast, but rather a prediction. (admittedly I am being very nit-picky here). In many domains the difference between predicting and forecasting is that the former produces a single value as an outcome, whilst the latter produces a range of possible outcomes with probabilities assigned to values within the range. For example, a few decades ago weather predictions were just that: predictions. For a few days into the future the prediction would be a given high temperature and whether it would rain or not. Today that has evolved to a true forecast, where temperatures are frequently provided in ranges and rain is given a certain probability of occurring. The difference in output between forecasting and demand modeling is the same.
Traditional forecasting produces a series of values, each being a single point prediction of demand for a given future time period. Demand modeling on the other hand produces ranges of values for for each such given time period. These ranges are not merely an upper limit and a lower limit of expected demand; rather each value within each range has a known probability of occurring. And it bears repeating that this probability follows a distribution that is determined in a highly reliable way from historic demand and other influences, not conveniently assuming a normal distribution.
When this concept is explained many statisticians frequently exclaim that statistical forecasting provides the same via confidence limits. This however is very far from reality. First, the confidence limits are based on an assumed probability distribution, typically the normal distribution, which in most cases is highly inaccurate. Second, they turn a 1-number prediction into a 3-number prediction, still infinitely far away from a continuous spectrum. Last, and most important, these confidence limits are not based on the uncertainty of the demand, nor even the inherent variability of the demand, but rather on the estimated error of the chosen forecast algorithm. In the two next figures first an example of a prediction with confidence limits is shown and in the next one the equivalent true forecast including the demand uncertainty:
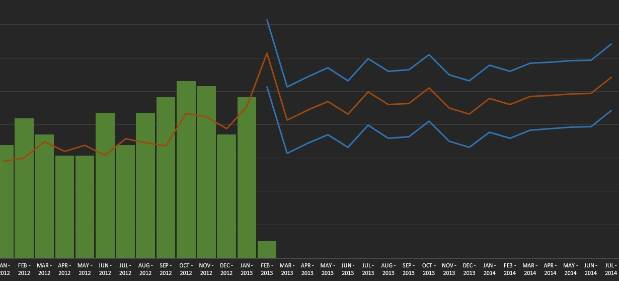
Demand forecast (red line) plus its 2 confidence limits (blue lines). Green bars are historic demand.
This graph was manually created in MS Excel, just for explanatory purposes. Colors were chosen to resemble the next screenshot to illustrate the equivalent and comparative measures. In the above graph note that the confidence limits are both symmetrical (blue lines are equally far from the red line) as well as equi-distant (equally far from the red line across the entire time axis). Neither of these characteristics is realistic for demand uncertainty. Note that I used an additive factor to represent the confidence limits for explanatory purposes. With a more common multiplicative factor the graph would not illustrate the point well, but it would still apply: the ranges are still equi-distant, just in relative terms rather than absolute terms.

Same forecast and demand history, now with demand uncertainty (blue bars).
This graph is a screen capture from ToolsGroup's Service Optimizer 99+. It clearly shows the asymmetry of the demand uncertainty (bars above the red forecast line are longer than those below) and only barely visible are the minor differences in length of the bars in time. The different shades of blue and purple in the bars demarc zones of uncertainty. If this were a normal distribution (which it clearly is not, witness the asymmetry) you could consider light blue to denote 1 sigma (1 standard deviation), purple 2 sigma, and dark blue 3 sigma. This is purely a visual simplification, where the application holds the complete richness of the uncertainty profile.
For this demand pattern belonging to a semi-fast moving item the symmetric and equi-distant confidence limits are clearly inadequate. The confidence on the low end is likely highly over-estimated, whilst the confidence on the high end is likely highly under-estimated. This also translates into highly erroneous safety stock setting, in most cases similar to the above demand pattern where the top-side is under-estimated and targeted service levels are never achieved. Simultaneously for slow-moving items the over-estimation on the bottom side usually means generating a lot of inventory destined to become obsolete. More on this in a post on inventory optimization in the near future.
So, the output of demand modeling is much richer than that of statistical forecasting. But what can you do with all that richness?
If you implement this process in a legacy environment where no other system is stochastic in nature, most of that richness is lost. You would be limited to integrating the output in a format that traditional deterministic systems understand. However, even though the format is limited, the reliability of values is much greater. For example, the forecast itself, which in demand modeling is merely a by-product of the demand uncertainty, will be in the same format as traditional forecasting systems would provide. The quantities forecasted would just have a much lower forecast error. Similarly a single demand variability value could be provided per data series to input into legacy safety stock calculations. Again, the reliability of that value would be much greater.
When integrated with other stochastic systems or modules the full richness can be maintained and further improve quality of the calculations and results of such systems. Inventory optimization is an example, but transportation planning, S&OP, production scheduling, supply chain planning, and theoretically even WMS are all examples of areas where significant improvements can be achieved when preserving that richness.
Naturally within a demand modeling system itself, the deep understanding of demand and the uncertainty around it can provide enormous value to the user and to the business. That value will be the topic of multiple other parts in this series, so I will not dwell on it here.
The next part in this series will go into greater detail of the basic concepts of demand modeling.










